
Key Takeaways
- Australia's largest retailer, Woolworths, is making Mandy, the AI assistant in its Everyday loyalty app, fully agentic. The shopper-facing Olive already handles over 70 percent of contact-centre interactions and moves from internal preview to consumer availability in July
- The core is eight proprietary agentic judges that automatically vet every response before it reaches a customer, running number recalculation, legal checks, and goal verification as a separate layer. It is a production-grade hallucination-control architecture
- For EC and retail operators, this is a concrete reference model for the hardest question in deploying agents: how to design governance when you put an AI agent into live operation
Woolworths Makes Mandy Fully Agentic, Olive Reaches Consumers in July
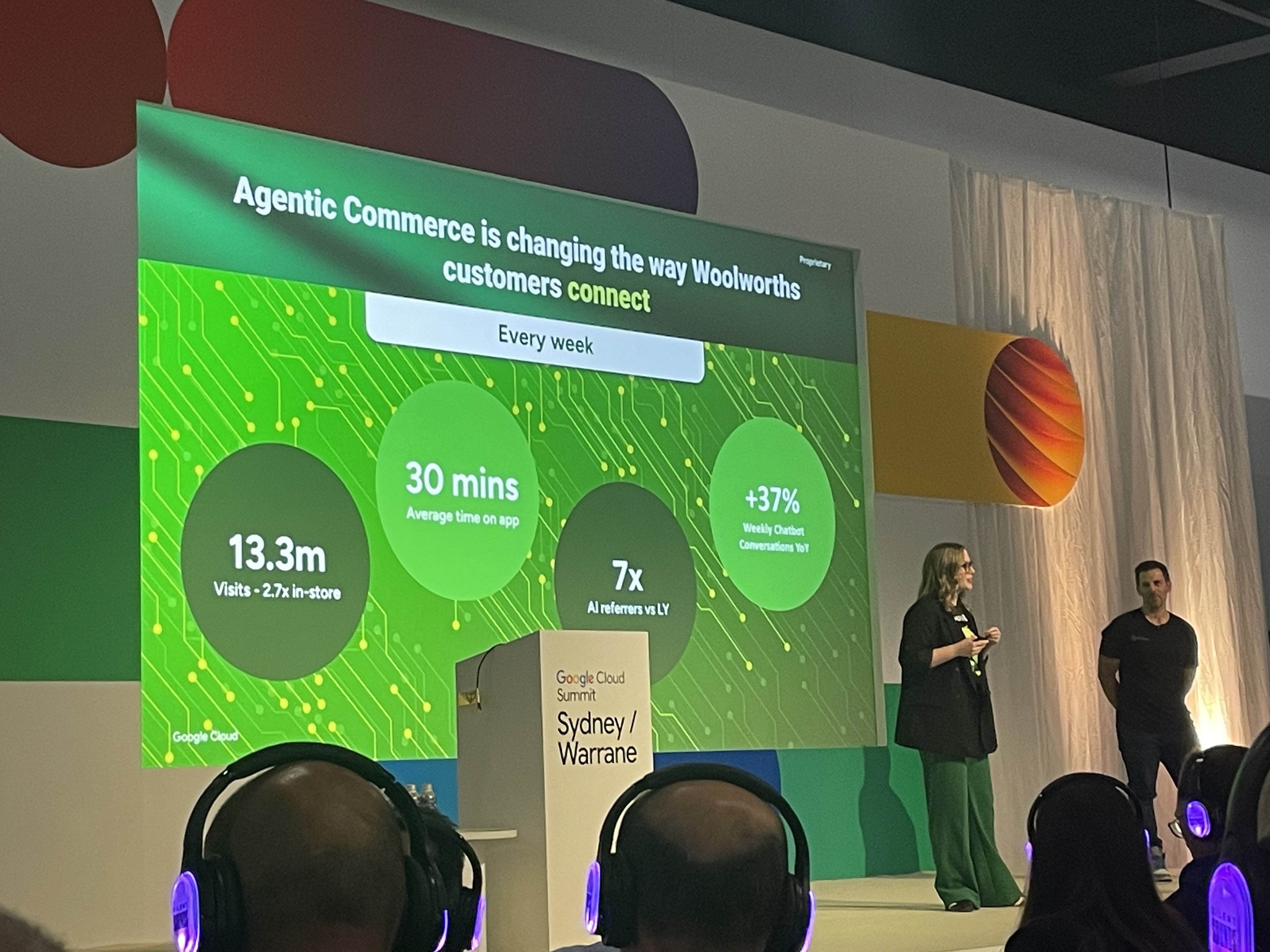
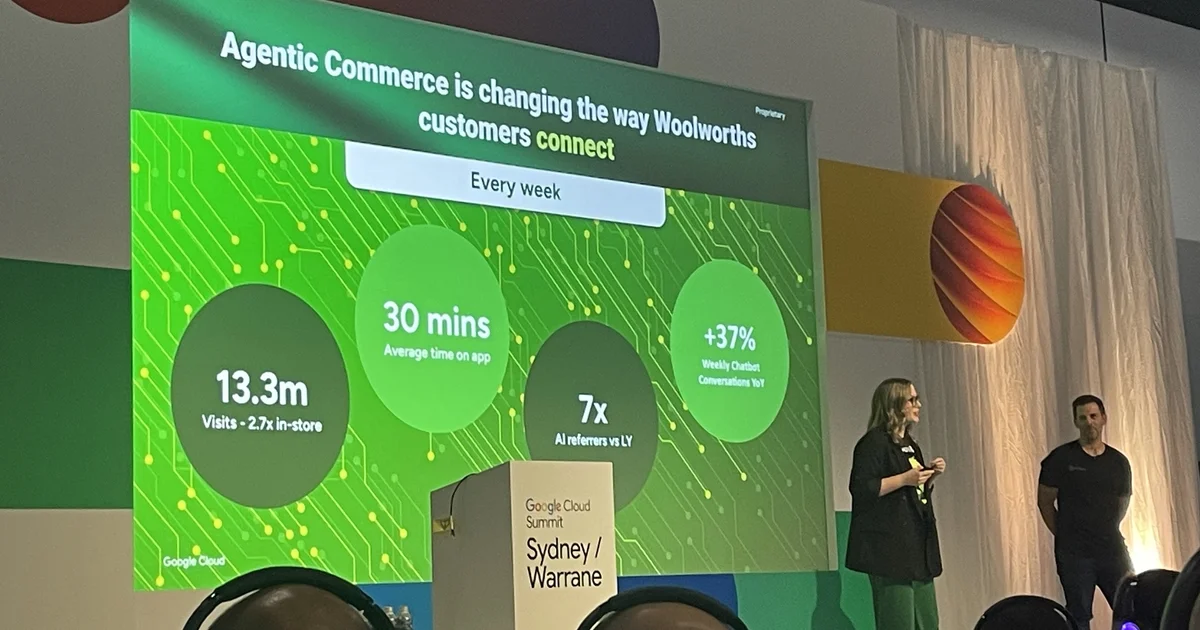
Woolworths has disclosed plans to upgrade Mandy - the AI assistant embedded in its Everyday loyalty, mobile, and insurance products - to a fully agentic system.
letsdatascience.comWoolworths, the largest retailer in Australia and the Asia-Pacific region, is making two AI assistants agentic in quick succession. One is Olive, which handles service and inquiries; the other is Mandy, embedded in the Everyday loyalty app. In June 2026, the company's AI customer experience lead Katharyn Moger said, "I'm really proud to say that we're expanding to agentic loyalty," confirming plans to make Mandy agentic across the Everyday brand, including its insurance and mobile businesses.
The numbers behind the earlier rollout of Olive stand out. According to company executives, Olive already handles over 70 percent of contact-centre interactions. After two months of testing by more than 200,000 staff, Olive will finally reach general shoppers in July. The foundation is Google Cloud's Gemini Enterprise for Customer Experience (GECX). Using this platform, Woolworths rebuilt Olive from a "deterministic chat and voice bot" into a full agent in roughly six months.
As news, this could easily read as just another retailer upgrading an AI assistant. But the value lies elsewhere. Woolworths disclosed, with unusual specificity for the industry, the inside of its governance: how it validates an agent's output before delivering it to customers. That is the part this article digs into most deeply.
Eight Agentic Judges Vet Every Response
When you put an AI agent into live operation, the first wall everyone hits is the risk of delivering a wrong answer straight to the customer. Misstating a price, recommending an out-of-stock item, missing a food-allergy or legal disclosure. For a chatbot, that might be a harmless slip. For an agent that builds a basket and even completes payment on the customer's behalf, it becomes an incident.
Woolworths' answer was not to rely on the model's own guardrails, but to build a self-made independent validation layer in which another AI reviews the response. At Google Cloud Next '26 in Las Vegas in April 2026, technology director Venky Erode Sivasubramaniyam demonstrated the eight agentic judges running behind Olive. What matters is that this is not a model-level safety feature, but a separate layer the Woolworths team built "proprietarily." When the agent generates an answer, these eight judges automatically scrutinise the content in the background before it reaches the customer.
The three judges named explicitly capture the design philosophy well.
The number cruncher recalculates every numeric claim in a response: the best unit price, the price of the item, the ingredients in the item, the serving size of a recipe. It exists to "make sure that whatever the agent is providing, that it's actually giving the right accurate information to our customers." The agent produces the number, and a separate judge runs the calculation again to verify it. Separating generation from arithmetic is a practical prescription for numeric hallucination.
The product detective checks whether the agent's descriptions meet legal, food-safety, and compliance requirements. For a food retailer, labelling regulations are a lifeline of the business, and building that check into an automated layer rather than relying on manual review is no small matter.
The goal judge verifies that the agent completed its mission without error. Sivasubramaniyam's example is concrete: "When you give it a mission, saying, 'Build a basket within 20 bucks for a dinner tonight and it should include a roasted chicken', if the agent accidentally comes back at $25, then the goal is not met and it would fail the use case and immediately alert us to the issue." It separates a task that merely looks complete from one that is genuinely achieved, detecting failures and escalating them to humans.
Why go this far? Sivasubramaniyam's words are the answer: "You need something like this bunch of agentic judges to actually implement products like agentic commerce or agentic solutions to scale across organisations and customers, particularly when you have a large audience." At the scale of 200,000 staff, and the millions of shoppers beyond them, producing probabilistically correct responses is not enough. The practical judgment is that you need a layer that structurally guarantees you will not deliver mistakes to customers.
Why "AI Judging AI" Works
The crux of this eight-judge approach is that it separates the responsibilities of generation and verification. Asking a single large model to "answer correctly and also check your own mistakes" is like having the person who wrote the exam grade it. The same assumptions and hallucinations tend to slip through self-grading.
Woolworths avoids this by lining up multiple specialised reviewers. A number-specialist judge handles the math, a compliance-specialist judge handles regulation, a goal-specialist judge handles mission completion. Because each has a single axis of judgment, the pass/fail boundary becomes clearer than a general model's vague "roughly correct." It is easiest to understand as an implementation of the "LLM-as-a-judge" idea, evaluating an LLM's output with an LLM, mapped onto real commerce requirements.
The takeaway for EC and retail implementers is plain. If you put an agent at the customer touchpoint, do not bet on the model's intelligence; build a separate layer that independently inspects the output. And derive that layer's axes by working backward from "items that could become incidents in your own business": price calculation, inventory consistency, regulatory labelling, whether a budget or condition was met. Woolworths' three named judges translate directly into a checklist for many businesses. The fail-safe path, where a failed check is never shown to the customer but escalated to a human, is also part of the design and should not be overlooked.
Built on Google Cloud GECX, With Proactive Suggestions Ahead
Olive and Mandy run on Gemini Enterprise for Customer Experience (GECX), which Google Cloud announced at NRF in January 2026. It unifies shopping and customer service into a single interface and bundles search, reasoning, multimodal understanding (voice, image, video), and backend connectivity into a "proactive digital concierge." Woolworths was the first retailer in Asia-Pacific to adopt it; in the US, Kroger, Lowe's, and the restaurant chain Papa Johns have also deployed it.
The Olive demo at Cloud Next '26 showcased its capabilities well. It built a basket from "please add eggs, bread, and a couple of other things for dinner tonight," swapped items for organic options, recognised a recipe from a meal photo (identifying spaghetti carbonara and adding the ingredients), and presented the amount saved, all in a single conversation. Sivasubramaniyam noted, "People are going through a lot of cost of living crisis, so they want cheaper product options," emphasising the response to cost-conscious shoppers.
What Woolworths is eyeing next is the proactive basket. The agent would pre-assemble a weekly staple basket and start the conversation from there, a feature still ahead of release. On the data rationale, Sivasubramaniyam said, "Don't quote me on the maths, but I believe about 80 percent of our groceries are repeat purchases," explaining that the high rate of repeat buying underpins proactive suggestions. At the same time, a feature where the agent begins assembling a basket before the user asks introduces new questions of consent design and opt-in transparency. How recommendations are disclosed, and whether bias toward promoted items emerges, are flagged by ABC News as open questions.
Conclusion
The Woolworths case shows, with concrete numbers and architecture, that the genuinely hard part of running AI agents in production is not "choosing a smart model" but "building a mechanism that never delivers mistakes to customers." The design of eight judges vetting every response is a reproducible reference model that keeps hallucination control and governance from staying abstract.
What to watch: whether this eight-judge approach spreads to other GECX adopters and becomes an industry-standard pattern; and how far Mandy's full agentic conversion and Olive's proactive basket get implemented, with consent design in place. The 70 percent contact-centre figure already speaks to the maturity of automation in numbers. Before running an agent at your own customer touchpoint, design which reviewers to stand up first. That is the practical homework Woolworths leaves behind.


